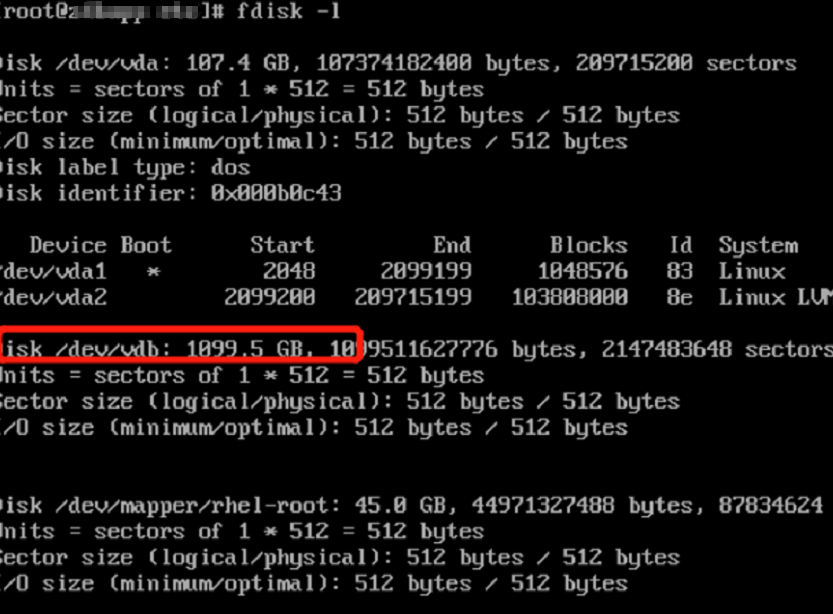
This article applies to BIG-IP iSeries hardware platforms.
Description
The LCD panel provides the ability to manage and monitor the unit without attaching a console or network cable. The different sensors that exist in the hardware platform provides information regarding the hardware health of the system by way of messages on the LCD screen. The following tables list messages that can appear on the LCD screen of iSeries platforms.
- PSUx Status sensor messages
- Power Fault sensor messages
- CPU Fault sensor messages
- Filter sensor messages
- LCD Health sensor messages
- Module Presence sensor messages
- Leonardo Daughter Card Absent messages
- FIPS Initialization Status messages
- RAID Disk Failure messages
The PSUx sensor is a discrete sensor based on the Intelligent Platform Management Interface (IPMI) standard sensor type code of 0x8. The sensor indicates various power supply unit (PSU) states.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| PSUx Status present | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status present | .1.3.6.1.4.1.3375.2.4.0.190 |
| PSUx Status absent | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status absent | .1.3.6.1.4.1.3375.2.4.0.190 |
| PSUx Status input lost | Warning | BIGIP_LIBHAL_AOM_SENSOR_PWR_WARN | 012a0040 | PSU# Status input lost | .1.3.6.1.4.1.3375.2.4.0.185 |
| PSUx Status input active | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status input active | .1.3.6.1.4.1.3375.2.4.0.190 |
| N/A | Notice | BIGIP_LIBHAL_CHASSIS_PS1_POWERED_ON BIGIP_LIBHAL_CHASSIS_PS2_POWERED_ON BIGIP_LIBHAL_CHASSIS_PS3_POWERED_ON BIGIP_LIBHAL_CHASSIS_PS4_POWERED_ON BIGIP_LIBHAL_CHASSIS_PS_POWERED_ON BIGIP_LIBHAL_CHASSIS_PS_IS_POWERED_ON | 012a0046 012a0047 012a0048 012a0049 012a0017 012a0019 | Chassis power module 1 turned on. Chassis power module 2 turned on. Chassis power module 3 turned on. Chassis power module 4 turned on. Chassis power module # turned on. Chassis power module # is on. | .1.3.6.1.4.1.3375.2.4.0.147 |
| N/A | Warning | BIGIP_LIBHAL_CHASSIS_PS1_POWERED_OFF BIGIP_LIBHAL_CHASSIS_PS2_POWERED_OFF BIGIP_LIBHAL_CHASSIS_PS3_POWERED_OFF BIGIP_LIBHAL_CHASSIS_PS4_POWERED_OFF BIGIP_LIBHAL_CHASSIS_PS_POWERED_OFF BIGIP_LIBHAL_CHASSIS_PS_IS_POWERED_OFF | 012a0050 012a0051 012a0052 012a0053 012a0018 012a0020 | Chassis power module 1 turned off. Chassis power module 2 turned off. Chassis power module 3 turned off. Chassis power module 4 turned off. Chassis power module # turned off. Chassis power module # is off. | .1.3.6.1.4.1.3375.2.4.0.148 |
| N/A | Notice | BIGIP_LIBHAL_CHASSIS_PS1_ABSENT BIGIP_LIBHAL_CHASSIS_PS2_ABSENT BIGIP_LIBHAL_CHASSIS_PS3_ABSENT BIGIP_LIBHAL_CHASSIS_PS4_ABSENT BIGIP_LIBHAL_CHASSIS_PS_ABSENT | 012a0054 012a0055 012a0056 012a0057 012a0021 | Chassis power module 1 absent. Chassis power module 2 absent. Chassis power module 3 absent. Chassis power module 4 absent. Chassis power module # absent. | .1.3.6.1.4.1.3375.2.4.0.149 |
| Power supplies do not match | Critical | BIGIP_LIBHAL_CHASSIS_PSU_MISMATCH | 012a0060 | Power supplies do not match. PSU #: modelnumber PSU #: modelnumber | N/A |
| PSUx Status config mismatch | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | PSU# Status config mismatch | .1.3.6.1.4.1.3375.2.4.0.188 |
| PSUx Status config match | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status config match | .1.3.6.1.4.1.3375.2.4.0.190 |
| PSUx Status output lost | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | PSU# Status output lost | .1.3.6.1.4.1.3375.2.4.0.188 |
| PSUx Status output active | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status output active | .1.3.6.1.4.1.3375.2.4.0.190 |
| PSUx Status PSU unidentified | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | PSU# Status PSU unidentified | .1.3.6.1.4.1.3375.2.4.0.188 |
| PSUx Status identified | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | PSU# Status PSU identified | .1.3.6.1.4.1.3375.2.4.0.190 |
The Power Fault sensor is a discrete sensor indicating that a power fault has occurred.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| Power Fault host asserted | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | Power Fault host asserted | .1.3.6.1.4.1.3375.2.4.0.188 |
| Power Fault host deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | Power Fault host deasserted | .1.3.6.1.4.1.3375.2.4.0.190 |
| Power Fault bay X asserted | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | Power Fault bay # asserted | .1.3.6.1.4.1.3375.2.4.0.188 |
| Power Fault bay X deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | Power Fault bay # deasserted | .1.3.6.1.4.1.3375.2.4.0.190 |
| Power Fault switchboard asserted | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | Power Fault switchboard asserted | .1.3.6.1.4.1.3375.2.4.0.188 |
| Power Fault switchboard deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | Power Fault switchboard deasserted | .1.3.6.1.4.1.3375.2.4.0.190 |
| Power Fault HDD x asserted | Critical | BIGIP_LIBHAL_AOM_SENSOR_PWR_CRIT | 012a0043 | Power Fault HDD # asserted | .1.3.6.1.4.1.3375.2.4.0.188 |
| Power Fault HDD x deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_PWR_INFO | 012a0045 | Power Fault HDD # deasserted | .1.3.6.1.4.1.3375.2.4.0.190 |
The CPU Fault sensor is a discrete sensor indicating that a CPU fault has occurred.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| CPU Fault CATERR asserted | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CPU Fault CATERR asserted | .1.3.6.1.4.1.3375.2.4.0.170 |
| CPU Fault CATERR deasserted | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU Fault CATERR deasserted | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU Fault THERMTRIP asserted | Emergency | BIGIP_LIBHAL_AOM_SENSOR_TEMP_EMERG | 012a0032 | CPU Fault THERMTRIP asserted | .1.3.6.1.4.1.3375.2.4.0.177 |
| CPU Fault THERMTRIP deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_TEMP_INFO | 012a0033 | CPU Fault THERMTRIP deasserted | .1.3.6.1.4.1.3375.2.4.0.178 |
| CPU Fault PROCHOT asserted | Critical | BIGIP_LIBHAL_AOM_SENSOR_TEMP_CRIT | 012a0031 | CPU Fault PROCHOT asserted | .1.3.6.1.4.1.3375.2.4.0.176 |
| CPU Fault PROCHOT deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_TEMP_INFO | 012a0033 | CPU Fault PROCHOT deasserted | .1.3.6.1.4.1.3375.2.4.0.178 |
| CPU Fault FIVR asserted | Emergency | BIGIP_LIBHAL_AOM_ALERT_EMERG | 012a0026 | CPU Fault FIVR asserted | .1.3.6.1.4.1.3375.2.4.0.171 |
| CPU Fault FIVR deasserted | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU Fault FIVR deasserted | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU Fault DIMM Event asserted | Warning | BIGIP_LIBHAL_AOM_ALERT_WARN | 012a0022 | CPU Fault DIMM asserted | .1.3.6.1.4.1.3375.2.4.0.167 |
| CPU Fault DIMM Event deasserted | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU Fault DIMM deasserted | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU Fault MEMHOT asserted | Warning | BIGIP_LIBHAL_AOM_SENSOR_TEMP_WARN | 012a0028 | CPU Fault MEMHOT asserted | .1.3.6.1.4.1.3375.2.4.0.173 |
| CPU Fault MEMHOT deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_TEMP_INFO | 012a0033 | CPU Fault MEMHOT deasserted | .1.3.6.1.4.1.3375.2.4.0.178 |
| CPU Fault VR Hot asserted | Warning | BIGIP_LIBHAL_AOM_SENSOR_TEMP_WARN | 012a0028 | CPU Fault VR Hot asserted | .1.3.6.1.4.1.3375.2.4.0.173 |
| CPU Fault VR Hot deasserted | Info | BIGIP_LIBHAL_AOM_SENSOR_TEMP_INFO | 012a0033 | CPU Fault VR Hot deasserted | .1.3.6.1.4.1.3375.2.4.0.178 |
| CPU Fault CPU IERR asserted | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CPU Fault IERR asserted | .1.3.6.1.4.1.3375.2.4.0.170 |
| CPU Fault CPU IERR deasserted | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU Fault IERR deasserted | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU Fault CPU MCERR asserted | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CPU Fault MCERR asserted | .1.3.6.1.4.1.3375.2.4.0.170 |
| CPU Fault CPU MCERR deasserted | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU Fault MCERR deasserted | .1.3.6.1.4.1.3375.2.4.0.172 |
The Filter sensor sends an event when the chassis filter needs to be replaced. This is a threshold-based sensor.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| Chassis air filter replacement due | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | Chassis air filter replacement due | .1.3.6.1.4.1.3375.2.4.0.172 |
| Chassis air filter replacement overdue | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | Chassis air filter replacement overdue | .1.3.6.1.4.1.3375.2.4.0.170 |
The LCD Health sensor indicates whether or not the BMC can communicate with the LCD.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| LCD Health communication OK | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | LCD Health communication OK | .1.3.6.1.4.1.3375.2.4.0.172 |
| LCD Health communication error | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | LCD Health communication error | .1.3.6.1.4.1.3375.2.4.0.170 |
Module Presence sensor messages
The Module Presence sensor indicates whether or not a module is present.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| fan tray present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | fan tray present | .1.3.6.1.4.1.3375.2.4.0.172 |
| fan tray absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | fan tray absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| bay x present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | bay # present | .1.3.6.1.4.1.3375.2.4.0.172 |
| bay x absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | bay # absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| switchboard present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | switchboard present | .1.3.6.1.4.1.3375.2.4.0.172 |
| switchboard absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | switchboard absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| LCD present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | LCD present | .1.3.6.1.4.1.3375.2.4.0.172 |
| LCD absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | LCD absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| CPU 00 present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU 00 present | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU 00 absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CPU 00 absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| CPU 01 present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CPU 01 present | .1.3.6.1.4.1.3375.2.4.0.172 |
| CPU 01 absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CPU 01 absent | .1.3.6.1.4.1.3375.2.4.0.170 |
Leonardo Daughter Card Absent messages
A single general-purpose input/output (GPIO) on Leonardo indicates that the daughter card is absent.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| CM Daughter Card absent | Critical | BIGIP_LIBHAL_AOM_ALERT_CRIT | 012a0025 | CM Daughter Card absent | .1.3.6.1.4.1.3375.2.4.0.170 |
| CM Daughter Card present | Info | BIGIP_LIBHAL_AOM_ALERT_INFO | 012a0027 | CM Daughter Card present | .1.3.6.1.4.1.3375.2.4.0.172 |
FIPS Initialization Status messages
The Federal Information Processing Standards (FIPS) Initialization Status sensor tracks the state of the Full Box FIPS Mode initialization for the host application.
| Alert message | Alert level | Alert name | Error code | Log message | Trap OID |
| FIPS initialization error asserted | Warning | BIGIP_LIBHAL_AOM_ALERT_WARN | 012a0022 | FIPS initialization error asserted | .1.3.6.1.4.1.3375.2.4.0.167 |
| FIPS initialization error deasserted | Warning | BIGIP_LIBHAL_AOM_ALERT_WARN | 012a0022 | FIPS initialization error deasserted | .1.3.6.1.4.1.3375.2.4.0.167 |
The RAID controller on a Dual-SSD system indicates that the member disk is removed from the RAID array.
| Alert Message | Alert Level | Alert Name | Error code | Log message | Trap OID |
| RAID disk failure. | Critical | BIGIP_RAID_DISK_FAILURE | 0x0 | Raid#:md#: Disk failure | .1.3.6.1.4.1.3375.2.4.0.96 |